")



.png)


Mission Assurance
.png?width=400&height=400&name=No%20background%20%20-%2030%20years%20logo%20(1).png)
Cloud-Native Model-Based Systems Engineering Software

.png?width=500&height=333&name=Desktop%20Screenshot%20Test%20Version%20Only%20(delete).png)
SPEC Innovations provides innovative, cloud-native software solutions that encompass the full lifecycle of a system or product through requirements to MBSE to Human-Performance, all powered by AI.
.svg)
Our training courses focus on the topics of DoDAF and Systems Engineering taught by experts in the field. We also have expansive training courses on our software, Innoslate and Sopatra. Courses can be taught in-person, on-site, or virtually.
.svg)
Our team of experts have specialized capabilities in systems engineering, digital engineering, proposal development, and DoDAF. Our goal is to provide our clients with innovative services and solutions in a timely, professional, and cost-effective manner.
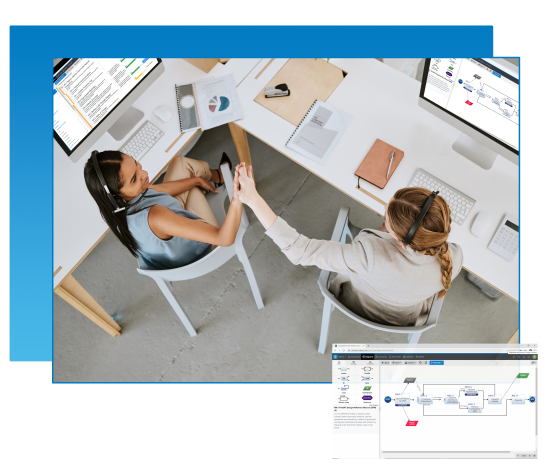
Innoslate is the first cloud-native, model-based systems engineering solution. Teams can work in real-time collaboration with version control in all areas of the product or system lifecycle.
Innoslate supports requirements management, modeling and simulation, verification and validation, program management, and more. See how Innoslate is the right solution for your team.
.png?width=64&height=64&name=target%20(3).png)
.png?width=64&height=64&name=evaluation%20(1).png)
.png?width=64&height=64&name=secure-shield%20(2).png)
.png?width=64&height=64&name=node%20(2).png)
.png?width=64&height=64&name=financial-report%20(7).png)
.png?width=64&height=64&name=chip%20(1).png)
.png?width=64&height=64&name=flow-chart%20(1).png)
.png?width=64&height=64&name=requirements%20(2).png)
.png?width=128&height=128&name=help%20(2).png)
We provide our clients with innovative services and solutions in a timely, professional, and cost-effective manner. We serve commercial, defense, aerospace, intelligence community, federal civilian agencies, energy, and more.